BigData > Data Engineering 과정
아파치 하둡으로 구축하는 분산처리 빅데이터 플랫폼
- 강의기간
-
교육 시작일 후 5일
- 난이도
- 중급
- 수강일
- 5일, 09:30~17:30
- 수강료
-
1,600,000원
KRW (KR)
- 환급
-
비환급과정
※ 비환급과정(면세) 입니다.
- 과목코드
- H8PT2
| ※ 본 과정을 신청하는 경우 한국 교육서비스의 Terms&Conditions 에 동의하는 것으로 간주합니다. |
| 과정소개 |
빅데이터 플랫폼, Hadoop Ecosystem 기술, HDFS, Mapreduce를 이해하고 하드웨어나 네트워크 등 실제 빅데이터 플랫폼 밥법을 설계합니다.
Hadoop Ecodesystem 기술을 이해하고, 빠른 데이터 분석을 위하 Spark의 기본적인 사용법 및 Hadoop 과의 연동을 합니다.
Spark Core, Spark SQL, Spark Stream, Spark MLlib를 이용하여 데이터 수집, 적재, 처리, 분석까지 빅데이터 분석 과정을 다룹니다.
|
| 수강대상 |
빅데이터 처리 분석 활용에 관심있는 모든 분들
|
| 교육내용 |
1일차 : Hadoop 기초와 빅데이터 플랫폼의 개념 및 설계 - 빅데이터 플랫폼과 하둡
- 빅데이터 플랫폼 구축계획
- Spark의 개념과 아키텍처를 이해
2일차 : Hadoop을 이용한 빅데이터 플랫폼 - 빅데이터 수집에 활용할 기술
- 빅데이터 실시간 적재에 활용한 기술
- 빅데이터 탐색에 횔용되는 기술
3일차 : 효율적인 데이터 처리와 분석을 위한 Hadoop Ecosystem - 빅데이터 분석에 활용 기술
- 제플린을 이용한 실시간 분석
4일차 : 빠른 데이터 분석을 위한 Spark - Spark 기본적인 사용법과 연동방법
- Spark SQL, Stream, MLlib
5일차 : 실전 빅데이터 분석 프로젝트 - 스파크로 실시간 처리 및 분석 이해와 실습
- 접속 로그 분석 결과를 실시간 대시보드에 표시하는 스파크 스트리밍 애플리케이션 작성
- 스파크와 H2O를 활용한 딥러닝을 사용한 회귀 예측
|
| 선수과목 |
|
| 다음과목 |
|
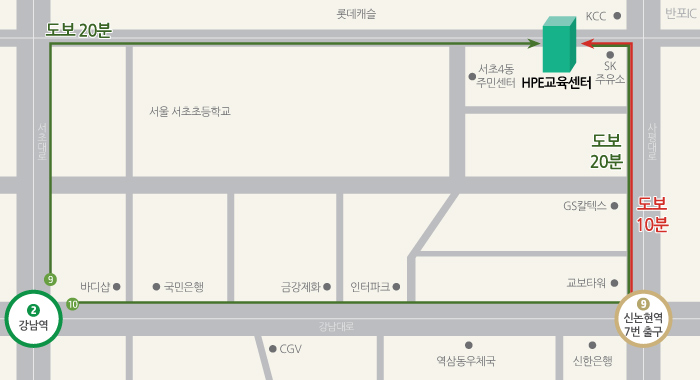
- 교육장
- 서울 한국HPE 강남교육센터
- 강의장
- 미지정
- 주소
- 서울 서초구 서초동 1302-2 대지프라자 6층
- 전화
- 1661-9080
- 팩스
- 02-3470-2200
- 주차
-
불가능
- 안내
-
- 9호선 신논현역 7번 출구 50M 직진, SK주유소에서 좌회전 후 30M 전방 도미노피자 건물 6F
- 2호선 강남역 9번 출구
시내버스 : 146, 341
마을버스 : 11 {삼호아파트 하차 (2 정거장)}
도보 : 강남역에서 20분 거리
* 주차불가

